兔子自己总结的一些面试题。题目会慢慢变多,答案也全部是自己写的,并非网上找的答案。
还有一篇Awesome Android Job Interview
Java 部分
String、StringBuffer、StringBuilder 区别
String 的值是不可变的,对 String 的每次操作都会生成新的对象。这会导致效率低,有可能会频繁触发 GC 机制。
StringBuffer 是线程安全的,速度较慢。它使用的方法是在各种操作方法上加上了synchronized关键字。
StringBuilder 是线程不安全的,速度较快。
StringBuffer 用在有多个线程可能会同时修改同一个字符串时使用。
StringBuilder 用在某一个线程内部比较合适。
String 为什么是不可变的?
我们看看 String 的部分代码就知道了:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
...
}
value 一旦被初始化,它的指针指向内存中的地址就不能再改变了。虽然 value 数组本身是可变的,但是 String 类并没有提供任何方法来改变这个私有的成员变量。所以有时substring()看起来似乎是改变了 String 的值,但其实是一着『偷梁换柱』,已经产生了新的对象。
我们来做个实验:
String a = "123";
String a = a.substring(1);
我们 debug 一下,看一下它的对象是否产生了变化。
当断点卡在第一行时,我们可以看到,a 对象是 515,如下图:
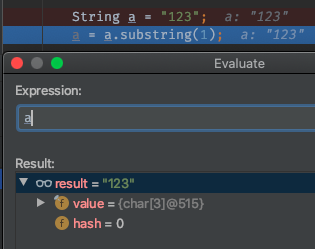
当执行完substring()方法后:
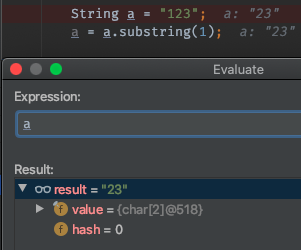
可见对象已经发生了变化,是 518 了。
这只是从代码层面解释了为什么 String 不可变。那 Java 这样设计的原因是什么?
- 安全层面。在 JDK 中,Java 的类装载机制通过传递的参数(通常是类名)加载类,这些类名在类路径下,想象一下,假设 String 是可变的,我们通过自定义类装载机制分分钟黑掉应用。如果没有了安全,Java不会走到今天。
- 性能层面。String 不可变的设计出于性能考虑,当然背后的原理是 String Pool,当然 String Pool 不可能使 String 类不可变,不可变的 String 能更好的提高性能。
- 线程安全。如果对象是不可变的,那绝对是线程安全的。
String Pool 是什么?
JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,即字符串池(String Pool)。字符串池由String类私有的维护。
我们知道,在Java中有两种创建字符串对象的方式:
- 采用字面值的方式赋值
- 采用
new关键字新建一个字符串对象。
这两种方式在性能和内存占用方面存在着差别。
方式一:字面方式赋值。
当我们采用下面的方式赋值的时候:
String str = "hello";
String str2 = "hello";
JVM首先会去字符串池中查找是否存在"hello"这个对象,如果不存在,则在字符串池中创建"hello"这个对象,然后将池中"hello"这个对象的引用地址返回给字符串常量str,这样str会指向池中"hello"这个字符串对象;如果存在,则不创建任何对象,直接将池中"hello"这个对象的地址返回,赋给字符串常量。
如果我现在调用str == str2会得到true。因为创建字符串str2时,在字符串池中已经有了"hello"这个对象,就直接把对象"hello"的引用地址返回给str2,这样str2指向了池中"hello"这个对象,也就是说str和str2指向了同一个对象,str == str2自然就是true。
方式二:用new关键字创建。
String str3 = new String("hello");
String str4 = new String("hello");
采用new关键字新建一个字符串对象时,JVM 首先在字符串池中查找有没有"hello"这个字符串对象,如果有,则不在池中再去创建"hello"这个对象了,直接在堆中创建一个"hello"字符串对象,然后将堆中的这个"hello"对象的地址返回赋给引用str3,这样,str3就指向了堆中创建的这个"hello"字符串对象;如果没有,则首先在字符串池中创建一个"hello"字符串对象,然后再在堆中创建一个"hello"字符串对象,然后将堆中这个"hello"字符串对象的地址返回赋给str3引用,这样,str3指向了堆中创建的这个"hello"字符串对象。
然鹅,这两个是用new创建的对象,str3和str4指向的必然不是同一个对象,堆中创建的两个"hello"并不是同一块内存区域,所以调用str3 == str4的话,返回的是false。
诚然,使用字符串池得有个前提条件:String 对象是不可变的。因为这样可以保证多个引用可以同时指向字符串池中的同一个对象。如果字符串是可变的,那么一个引用操作改变了对象的值,对其他引用会有影响,这样显然是不合理的。
优点:避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能。
缺点:牺牲了 JVM 在常量池中遍历对象所需要的时间,不过其时间成本相比而言比较低。
值得说明的是,字符串池中维护了共享的字符串对象,这些字符串不会被 GC 回收。
静态代理、动态代理,区别是什么?
静态代理通常只能代理一个类,每代理一个类,就需要多写一个类,这个类会被编译进 .class 文件中。
动态代理是在运行时,获取被代理类的 class 对象,通过 Java 提供的 Proxy 类来获取代理对象。它的本质是用 Class 来制造 Class。
父类的静态方法能否被子类重写?
不能。重写指的是根据运行时对象的类型来决定调用哪个方法,而不是根据编译时的类型。对于静态方法和静态变量来说,虽然在代码中使用子类对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。
单例模式的分类?
饿汉式:在类加载时就构建实例,立即初始化:
/**
* 饿汉式(推荐)
*
*/
public class Test {
private Test() {}
private static Test instance = new Test();
public Test getInstance() {
return instance;
}
}
优点:因为类在加载时就构建,所以是线程安全的;在类加载的同时已经创建好一个静态对象,调用时反应速度快。
缺点:getInstance()可能永远不会执行到,但执行该类的其他静态方法或者加载了该类(class.forName),那么这个实例仍然会初始化,造成资源浪费。
懒汉式:在初次使用时初始化,延迟加载:
class Test {
private Test() {
}
private static Test instance = null;
public static Test getInstance() {
if (instance == null) {
instance = new Singleton2();
}
return instance;
}
}
优点:避免了饿汉式的那种在没有用到的情况下创建事例,资源利用率高,不执行getInstance()就不会创建实例,可以执行该类的其他静态方法。
缺点:线程不安全。懒汉式在单个线程中没有问题,但多个线程同时访问的时候就可能同时创建多个实例,而且这多个实例不是同一个对象,虽然后面创建的实例会覆盖先创建的实例,但是还是会存在拿到不同对象的情况。解决这个问题的办法就是加锁synchonized,第一次加载时不够快,多线程使用不必要的同步开销大。
那么如何构建线程安全的懒汉式单例呢?
第一种思考,在getInstance()上加上个同步锁:
class Test {
private Test() {
}
private static Test instance = null;
public synchonized static Test getInstance() {
if (instance == null) {
instance = new Singleton2();
}
return instance;
}
}
问题可以得到解决,但是因为synchronized关键字是重量级锁,所以上面代码的效率会比较低。有没有改善方案?
有。在这里我们引入双检查锁机制,在线程安全的同时,又能进一步提高效率:
public class Test {
private Test() {
}
volatile private static Test instance = null; // 使用 volatile 关键字保证内存可见性
public static Test getInstance() {
if(instance != null){ //懒汉式
return instance;
} else {
synchronized (Test.class) {
if (instance == null){ // 二次检查
instance = new Test();
}
}
}
return instance;
}
}
这里在声明变量时使用了volatile关键字来保证其线程间的可见性;在同步代码块中使用二次检查,以保证其不被重复实例化。集合其二者,这种实现方式既保证了其高效性,也保证了其线程安全性。
介绍一下注解
注解是一种类似注释的机制,告诉类如何运行。它可以应用于包、类型、构造方法、方法、成员变量、参数上。
Java 中的注解分为两大类:标准注解和元注解。
标准注解包括:
Override:限定重写父类方法,该注解只能用于方法;Deprecated:表示该程序元素已过时;SupressWarnings:抵制编译器的警告。
元注解包括:
Rention:标记在什么级别保存该注解信息,也即注解的生命周期,如 RentionPolicy.CLASS、RentionPolicy.RUNTIME 等;Documented:标识是否会被包含在 Javadoc 中;Target:标识注解的使用范围,如 ElementType.PARAMS、ElementType.FIELD 等;Inherited:标识该注解可以被子类继承;Repeatable:标识该注解可以被某个元素重复使用。
我们还可以自定义注解处理器来实现自己的注解处理方式。通常是自定义一个类,继承自 AbstractProcessor,然后覆写init()和process()方法,然后在 Jar 包的 META-INF/services 文件夹中,放入一个名为javax.annotation.processing.Processor的文件,并在文件中写下自定义类的包名。或者使用 Google 提供的注册处理器的库auto-service。
Collection 类有哪些子类?
有 List 和 Set。Map 中也使用到了 Collection。
List、Set、Map的区别
List 和 Set 是 Collection 类的子接口。Map 是一个单独接口。
List:
- 允许有重复的对象。
- 可以插入多个 null 元素。
- 是有序容器,保持了元素的插入顺序。
- 常用实现类有 ArrayList(线程不安全)、LinkedList(线程不安全) 和 Vector(线程安全)。
Set:
- 不允许有重复的对象。
- 只允许一个 null 元素。
- 是无序容器,无法保持取出时的顺序是插入时的顺序。
- 常用实现类有 HashSet(哈希表)、LinkedHashSet(链表和哈希表) 和 TreeSet(红黑树)。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
Map:
- Map 不是 Collection 的子接口或者实现类,它是一个单独的接口。
- Map 每个节点都持有两个对象,key 和 value。
- Map key 值必须是唯一的,value 不是。
- Map 允许 null value 但只能有一个 null key。
- Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
使用场景的区别:
- 如果你经常会使用 index 来对容器中的元素进行访问,那应该选择 List。如果你已经知道索引了的话,那么 List 的实现类比如 ArrayList 可以提供更快速的访问;如果经常添加删除元素的,那么肯定要选择 LinkedList。
- 如果你想容器中的元素能够按照它们插入的次序进行有序存储,那么还是 List,因为 List 是一个有序容器,它按照插入顺序进行存储。
- 如果你想保证插入元素的唯一性,也就是你不想有重复值的出现,那么可以选择一个 Set 的实现类,比如 HashSet、LinkedHashSet 或者 TreeSet。所有 Set 的实现类都遵循了统一约束比如唯一性,而且还提供了额外的特性比如 TreeSet 还是一个 SortedSet,所有存储于 TreeSet 中的元素可以使用 Java 里的 Comparator 或者 Comparable 进行排序。LinkedHashSet 也按照元素的插入顺序对它们进行存储。
- 如果你以 key-value 的形式进行数据存储那么 Map 是你正确的选择。你可以根据你的后续需要从 Hashtable、HashMap、TreeMap 中进行选择。
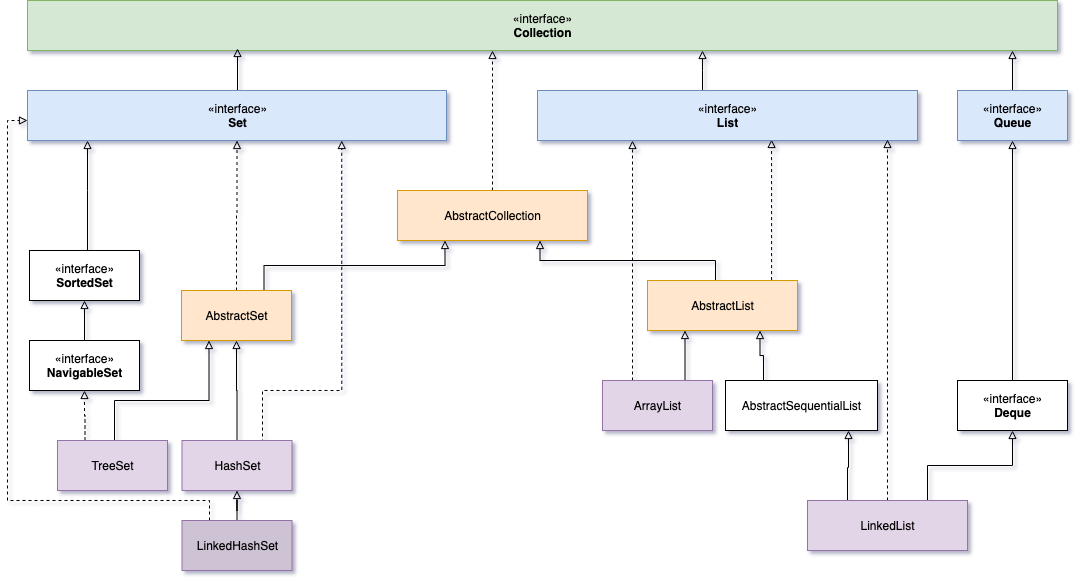
Collection 家族的关系表如下(并不全):
HashMap 的原理?
HashMap 是常见的用 key-value 存储的工具类,它的数据结构是数组+链表。每次插入新数据时,会使用一个算法去计算它应该插入的 index(key.hashCode & (size - 1)),如果当前位置没有数据,则直接插入,如果有数据,则用链表的形式插入该位置。JDK1.7和JDK1.8有区别,在1.7中使用的是头插法,也就是新插入的数据会替换原来的数据;1.8之后使用的是尾插法,也就是新插入的数据会跟在原来数据的后面。1.7的这种插法,因为改变了数据的顺序,有可能在多个线程插入时造成死循环,而1.8的这种方法就不会造成死循环了。但并不代表它就是线程安全的。如果想要线程安全,可以使用 Hashtable 或者 ConcurrentHashMap。每个 HashMap 默认大小是16,如果超过了它的负载因子(默认是0.75)的话,就会扩容。
HashMap 扩容的过程是怎样的?
数组的大小改为原来的2倍,所有的数据会重新计算 index 并重新插入。
那对比一下 Hashtable 和 ConcurrentHashMap?
Hashtable 只是在put/get方法上加上了synchronized关键字,并发度比较低。而 ConcurrentHashMap 在 JDK1.7 中采用了分段锁技术,其中 Segment 继承于 ReentrantLock。 每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。每一个 HashEntry 用volatile来修饰了它的value和next节点,以保证内存可见性。在 JDK1.8 中抛弃了 Segment 机制,使用了 CAS 和 synchronized 机制,将 HashEntry 替换为 Node,并把它的value和next也用volatile来修饰。
什么是浅拷贝和深拷贝
浅拷贝:
对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个。而对于引用类型,比如数组或者类对象,因为引用类型是引用传递,所以浅拷贝只是把内存地址赋值给了成员变量,它们指向了同一内存空间。改变其中一个,会对另外一个也产生影响。
简单来说,就是只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存区域,修改新对象时,原对象也会被修改。
要实现浅拷贝,需要实现 Cloneable 接口,并复写clone()方法。
浅拷贝会带来一定的安全隐患,因为新旧对象指向的是同一个地内存地址。
深拷贝:
对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(这一点和浅拷贝一样)。而对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。
简单来说,就是会创建另外一个一模一样的对象,新旧对象不共享内存,修改新对象不会更改到原对象。
深拷贝比浅拷贝的速度要慢并且开销较大。
要实现深拷贝,需要实现 Cloneable 接口,并复写clone()方法。
介绍一下 GC
GC 是 Java 的内存回收机制。当堆中有长时间不使用的内存块,GC 就会开始工作回收此部分内存,以供程序创建新的对象使用。
GC 分为 Minor GC 和 Major GC(Full GC),它们作用的内存区域不同:Minor GC 主要作用于新生代,一个包含 Eden 区、S0 区和 S1 区的内存区域。在进行 Minor GC 时,当前线程将会暂停。Major GC 主要作用于老年代,但是也会回收新生代的内存,这个过程会比较慢。
判定需要回收的对象的方法是使用可达性分析法。为什么不用引用计数法呢?因为引用计数法会导致循环引用的对象无法被回收。
可达性分析是指的,通过一系列被称为 GC Roots 的对象作为起点,从这些节点向下搜索,走过的路径称为引用链,如果一个对象到 GC Roots 没有任何引用链相连(不可达),则证明该对象不可用,可以进行回收。GC Roots 有个特点,不可被对象图里的对象所引用,所以不会引起循环引用的问题。
Minor GC 和 Major GC 触发的时机不相同:
- Minor GC 是当 Eden 区满时触发
- Major GC 有以下几种:
- 调用
System.gc()方法 - 老年代空间不足
- 方法区空间不足
- 通过 Minor GC 后进入老年代的平均大小大于老年代的可用内存
- 由 Eden 区、S0 区向 S1 区复制时,对象大小大于 S1 可用内存,则把该对象转存到老年代,且该对象大小大于老年代的可用内存
- 调用
GC 回收的常用算法有四种:
- 标记-清除算法:第一阶段标记不可用对象,第二阶段清除这些对象。不会改变原有数据的位置。会造成内存碎片空间。
- 标记-整理算法:是标记-清除的改进版。不同的是,在第二阶段,会将所存活的对象整理到另一个空间,然后把剩下的对象全部清除。不会造成内存碎片,但因为有大量复制,算法效率较低。
- 复制算法:将内存区域划分为相等大小的两部分,只使用一半空间,当需要 GC 时,将存活对象复制到另一半,并将之前的空间清除。不会产生内存碎片,但永远只能使用一半的内存。
- 分代收集算法:主流算法。它会根据对象的生存周期,将堆空间分为新生代和老年代。新生代中,每次回收都会有大量对象死去,此时使用复制算法;而老年代存活率较高,使用标记-清除或者标记-整理。
GC 的具体实现是垃圾收集器。
常用的有 Serial(复制算法,串行)、CMS(标记-清除算法,并发)、G1(标记-整理+复制算法,并发)等。
强引用、软引用、弱引用、虚引用分别是什么?区别是?
Java 的引用从强到弱分别是强引用、软引用、弱引用和虚引用。
强引用(StrongReference):
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。即便内存空间不足,JVM 宁愿抛出 OutOfMemory,也不会随意回收具有强引用的对象来解决内存不足的问题。如果强引用对象不使用时,需要将其『弱化』从而使 GC 能回收,比如置为 null。
软引用(SoftReference):
如果一个对象只具有软引用,则内存空间充足时,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
弱引用(WeakReference):
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
虚引用(PhantomReference):
虚引用顾名思义,就是形同虚设。与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
虚引用与软引用和弱引用的一个区别在于,虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
一张表格来展示一下四种引用:
| 引用类型 | 被垃圾回收时间 | 用途 | 生存时间 |
|---|---|---|---|
| 强引用 | 从来不会 | 对象的一般状态 | JVM停止运行时终止 |
| 软引用 | 当内存不足时 | 对象缓存 | 内存不足时终止 |
| 弱引用 | 正常垃圾回收时 | 对象缓存 | 垃圾回收后终止 |
| 虚引用 | 正常垃圾回收时 | 跟踪对象的垃圾回收 | 垃圾回收后终止 |
如何保证线程安全?
线程安全体现在三个方面:
原子性:同一时刻只能有一个线程对数据进行操作;
要保证原子性,可以使用 Java 提供的 Atomic 类,比如 AtomicInteger、AtomicLong 等。它们的原理是基于 CAS(Compare and Set),一种乐观锁。
也可以使用
synchronized关键字。synchronized是一种同步锁,依赖 JVM 实现锁机制,是一种以牺牲性能为代价的方法。它可以修饰四种对象:- 代码块:锁住括号内的对象;
- 非静态方法:锁住当前实例;
- 静态方法:锁住的是该类的 Class 对象;
- 类:锁住的是该类;
可见性:一个线程对主内存的修改可以及时地被其他线程看到;
保存可见性,可以使用
volatile关键字修饰变量。但它不是原子性的,比如像x++这种操作就无法保存其线程安全。有序性:禁止指令重排。
要保存有序性,使用
synchronized和volatile和 Lock 都可以。
synchronized 和 volatile 有什么区别?
synchronized保证内存可见性和操作原子性,volatile保证内存可见性和有序性;volatile不需要加锁,比synchronized更轻量级;volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞;volatile标记的变量不会被编译器优化,而被synchronized标记的部分可以被编译器优化(如指令重排);volatile是变量修饰符,仅能用于变量,而synchronized是一个方法或块的修饰符。
死锁的四个必要条件?如何处理?
死锁是指两个或两个以上的进程(线程)在运行过程中因争夺资源而造成的一种僵局(Deadly-Embrace),若无外力作用,这些进程(线程)都将无法向前推进。
它产生的四个必要条件是:
- 互斥条件:一个资源每次只能被一个进程使用,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待;
- 请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放;
- 不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放);
- 循环等待条件: 若干进程间形成首尾相接循环等待资源的关系。
避免死锁的基本思想是:系统对进程发出的每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源,如果分配后系统可能发生死锁,则不予分配,否则予以分配,这是一种保证系统不进入死锁状态的动态策略。
介绍一下线程池
线程池一般用来限制程序中同一时刻运行的线程数。合理利用线程池有三个好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗;
- 高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行;
- 提高线程的可管理性。使用线程池可以进行统一的分配,调优和监控。
JDK 中提供了ThreadPoolExecutor类,用来创建线程池。线程池中的线程分为两种:核心线程和非核心线程。核心线程永远不会被回收,而非核心线程在空闲达到一定时间后,就会被回收,这个时间由构造方法中的keepAliveTime参数来指定。
新建线程池时,可以指定核心线程数量、线程最大数量、空闲超时时长、阻塞队列类型、回收策略等。
根据初始化时核心线程数 + 非核心线程数 + 空间超时时长,衍生出了应对不同需求的线程池派生类,如:
- CachedThreadPool:没有核心线程,60秒空闲超时,比较适合执行很多短期异步的小程序或者负载较轻的服务器。
- FixedThreadPool:全部是核心线程,非常适合执行长期任务。因为所有线程都不会回收,所以能更快地响应执行任务的请求。
- SingleThreadExecutor:只有一个核心线程,适合一个任务一个任务按顺序执行的场景。
向线程池提交任务有两个方法:execute(Runnable)和submit(Callable)。它们的区别是execute()方法执行完后,无法得知任务是否已被执行,而submit()方法会返回一个 Future 用来获取执行结果。
线程池的终止有两个方法:shutdown()和shutdownNow()。它们都会关闭线程池,区别是shutdown()让线程池不再接收新任务,但已经添加的任务不受影响;shutdownNow()会尝试停止所有正在执行的任务,停止处理正在等待的任务,并返回正在等待的任务的列表。
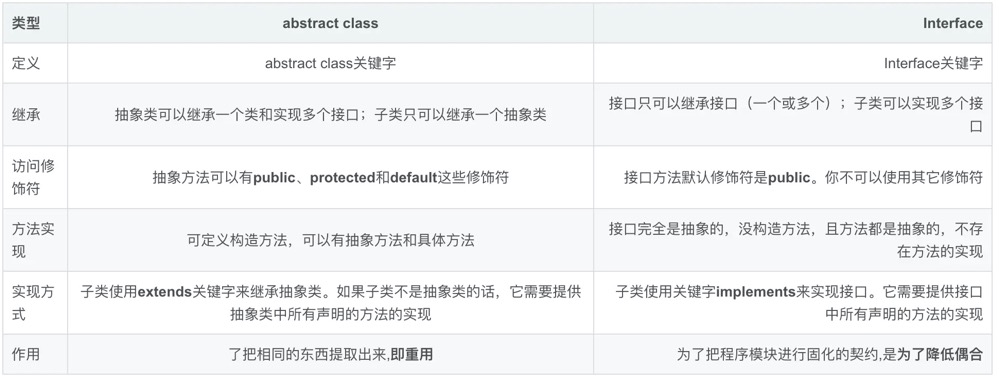
抽象类和接口的异同是什么?在什么场景下使用?
同:
- 它们都不能被实例化。
- 接口的实现类和抽象类的子类只有全部实现了接口或者抽象类中的方法后才可以被实例化。
异:
- jdk1.7 及以前,接口只能定义抽象方法不能实现方法,抽象类既可以定义抽象方法,也可以实现方法;但是,在 jdk1.8 之后,接口中也可以有默认的实现方法了,用 default 关键字修饰;
- 类只能继承一个类,但可以实现多个接口;
- 接口强调的是功能,抽象类强调的是所属关系;
- 接口中的所有成员变量为 public static final,静态不可修改,当然必须初始化。接口中的所有方法都是 public abstract 公开抽象的,而且不能有构造方法。抽象类就比较自由了,和普通的类差不多,可以有抽象方法也可以没有,可以有正常的方法,也可以没有;
- 接口表示的是like a关系,抽象类表示的是is a关系。
上图:
什么时候使用接口?
因为 Java 只能继承一个类,所以作为继承关系的补充,可以使用接口。同时,把程序模块进行固化的契约,降低耦合。把若干功能拆分出来,按照契约来进行实现和依赖,也即依赖倒置原则。定义接口有利于代码的规范,这是接口分离原则。
什么时候使用抽象类?
- 需要对类型进行隐藏时。我们可以构造出一个固定的一组行为的抽象描述,一个行为可以有任意个可能的具体实现方式。这个抽象的描述就是抽象类。
- 需要对类的行为进行拓展时。这一组任意个可能的具体实现表现为所有可能的子类,模块可以操作一个抽象类,由于模块依赖于一个固定的抽象类,那么他是不允许修改的。同时通过这个抽象类进行派生,拓展此模块的行为功能。
Android 部分
介绍一下 Android 的四大组件
Activity
Activity 是用户操作的可视化界面;负责与用户进行交互并处理事件。要使用它,必须要在 AndroidManifest.xml 中进行注册。它有四种启动模式:standard、singleTop、singleTask 和 singleInstance。它的生命周期是 onCreate - onStart - onResume - onPause - onStop - onDestroy。
Service
Service 通常用于在后台处理耗时的逻辑。要使用它,也必须要在 AndroidManifest.xml 中进行注册。启动服务并不会开启一个新的线程,它还是会默认运行在主线程中。它还有一个子类是 IntentService,它包含有一个 HandlerThread,所以可以在子线程中做耗时操作,而不会阻塞主线程。
启动 Service 的方法有两种:
startService():这种方法启动的 Service,启动之后就与启动者无关了,哪怕启动者退出了,Service 还会继续运行。bindService():这种方法启动的 Service,与启动者的生命周期有关,如果启动者退出,Service 也会挂掉。
BroadcastReceiver
广播是一种广泛运用的在应用程序之间传输信息的机制。要使用它,可以在 AndroidManifest.xml 中进行静态注册,也可以使用Context.registerReceiver()方法来动态注册。
两种注册方式是有区别的:动态注册广播不是常驻型广播,也就是说广播跟随 Activity 的生命周期。静态注册是常驻型,也就是说当应用程序关闭后,如果有信息广播来,程序也会被系统调用自动运行。
广播传递数据使用的是 Intent。
Broadcast 有三种分类:普通广播、有序广播和粘性广播。
- 普通广播:这种广播可以依次传递给各个处理器去处理;
- 有序广播:这种广播在处理器端的处理顺序是按照处理器的不同优先级来区分的,高优先级的处理器会优先截获这个消息,并且可以将这个消息删除
粘性广播:粘性消息在发送后就一直存在于系统的消息容器里面,等待对应的处理器去处理,如果暂时没有处理器处理这个消息则一直在消息容器里面处于等待状态,粘性广播的Receiver如果被销毁,那么下次重建时会自动接收到消息数据。发送粘性广播需要添加权限:android.permission.BROADCAST_STICKY
那么,现在发送广播可以调用以下三种方法:
sendOrderedBroadcast(): 该方法发出的广播只能被一个 receiver 接收到,它处理完成后,会向下一个 receiver 传播一个 result。它也可以直接将广播拦截,让其他的 receiver 无法接收到这个广播。receiver 可以通过调整优先级(android:priority属性)来优先接收该广播。如果几个 receiver 优先级相同,那它们会按照随机顺序获得广播。sendBroadcast(): 该方法发出的广播能够被所有 receiver 接收到。但是无法保证发出和接收的顺序是一致的。LocalBroadcastManager.sendBroadcast(): 该方法发出的广播只能被当前 APP 内的 receiver 接收。如果你的广播不需要跨进程,那就使用这个方法,它的效率比较高(因为不需要考虑 IPC),并且安全性也能得到保障。
Content Provider
ContentProvider 是应用程序间非常通用的共享数据的一种方式,也是Android官方推荐的方式。它通过 uri 来标识其它应用要访问的数据,通过ContentResolver 的增、删、改、查方法实现对共享数据的操作。还可以通过注册 ContentObserver 来监听数据是否发生了变化来对应的刷新页面。
它有几个主要的方法:
query():查询指定的数据并返回 Cursorinsert():添加数据delete():删除数据update():更新数据
数据访问的方法insert,delete和update可能被多个线程同时调用,此时必须是线程安全的。
Activity 的四种启动模式
分为两类:standard 和 singleTop 为一类,singleTask 和 singleInstance 为一类。
standard 和 singleTop 启动的 Activity 可多次实例化。它们的实例可以处于 ActivityStack 中的任何位置。相比之下,singleTask 和 singleInstance 只能实例化一次。
standard:可以被无限制地创建,每次通过 Intent 去启动这个 Activity,都会创建一个新的实例,并放入 ActivityStack 的栈顶。在 Android 5.0 之前,无论要启动的 Activity 是否跟当前 Activity 属于同一个应用,都会把目标 Activity 放在当前 Activity 的栈中。而5.0之后,如果是同一个应用,则放在当前栈,如果不是同一个,则会新建一个栈,将目标 Activity 放入。
singleTop:栈顶复用,也就是说,如果在 ActivityStack 的顶部已经有了该 Activity 的实例,就会调用它的onNewIntent方法,而不是再创建一个实例。如果在栈内有该 Activity 的实例,也会再创建一个新的实例,并放入栈顶。
singleTask:如果当前系统中已经存在了该种启动模式的 Activity,则将存在该 Activity 的栈置于前台(用户可见),同时调用它的onNewIntent方法。
- 如果源 Activity 的目标 Activity 属于同一个应用,目标 Activity 目前还没有实例,那就直接在栈顶创建该 Activity 的实例;如果已经有实例,那么将会清空该 Activity 实例上方的所有其他 Activity,让目标 Activity 处于栈顶位置。
- 如果源 Activity 和目标 Activity 不属于同一个应用,如果系统中没有目标 Activity 的实例,则会创建它的任务栈,并创建目标Activity的实例;如果已经有实例,则将存在该 Activity 的栈置于前台(用户可见),并且清空该 Activity 实例上方的所有其他 Activity,让目标 Activity 处于栈顶位置。
singleInstance:它几乎和 singleTask 一样,唯一不同的是,持有目标 Activity 的任务栈中只能有目标 Activity 一个 Actvitiy 实例,不能再有别的Activity 实例。
Activity状态保存与恢复
比如 Activity A 启动了 Activity B,A 由于某种原因被杀死回收资源了,在 Activity 被杀死之前可以使用Activity.onSaveInstanceState()方法中获取一个 Bundle,这个 Bundle 可以在 A 又重新启动时在onCreate()或者onRestoreInstanceState()方法中使用,用来恢复数据和 UI。
有些时候,onSaveInstanceState()是不会被调用的,它和onStop()、onPause()等生命周期方法不能混淆。比如当用户从 B 返回 A 的时候,B 中就不会再调用onSaveInstanceState(),因为它的实例已经被销毁,永远不会恢复。
onRestoreInstanceState()会在onStart()方法后被调用。虽然调用onCreate(Bundle)也能达到相同目的,但是使用这个方法的好处是,可以在一些初始化工作完成后,再来恢复数据。
Activity A 启动另一个Activity B 会调用哪些方法?如果B是透明主题的又或则是个DialogActivity呢 ?
我们不多说,直接做个实验:
我们在 Activity A 和 B 中,远用如下格式显示生命周期:
override fun onStart() {
super.onStart()
Log.d("CodingRabbit", "Activity A: onStart")
}
然后看一下跳转时的生命周期流程:
D/CodingRabbit: Activity A: onPause
D/CodingRabbit: Activity B: onCreate
D/CodingRabbit: Activity B: onStart
D/CodingRabbit: Activity B: onResume
D/CodingRabbit: Activity A: onStop
可见并不是 Activity A 的 onPause() 后立即走 onStop(),而是等待 Activity B 的 onResume() 走完后才走。
接下来我们把 Activity B 换成透明的试试。
<style name="Theme.Custom.Transparent" parent="Theme.AppCompat.NoActionBar">
<item name="android:background">#33000000</item>
<item name="android:windowNoTitle">true</item>
<item name="android:windowBackground">@android:color/transparent</item>
<item name="android:colorBackgroundCacheHint">@null</item>
<item name="android:windowIsTranslucent">true</item>
</style>
<activity android:name=".ActivityB"
android:theme="@style/Theme.Custom.Transparent">
然后看一下跳转时的生命周期:
D/CodingRabbit: Activity A: onPause
D/CodingRabbit: Activity B: onCreate
D/CodingRabbit: Activity B: onStart
D/CodingRabbit: Activity B: onResume
与上面的区别是,Activity A 并没有走 onStop() 方法。
按下返回键后:
D/CodingRabbit: Activity B: onPause
D/CodingRabbit: Activity A: onResume
D/CodingRabbit: Activity B: onStop
D/CodingRabbit: Activity B: onDestroy
说说 Apk 的打包过程?
先上个图:
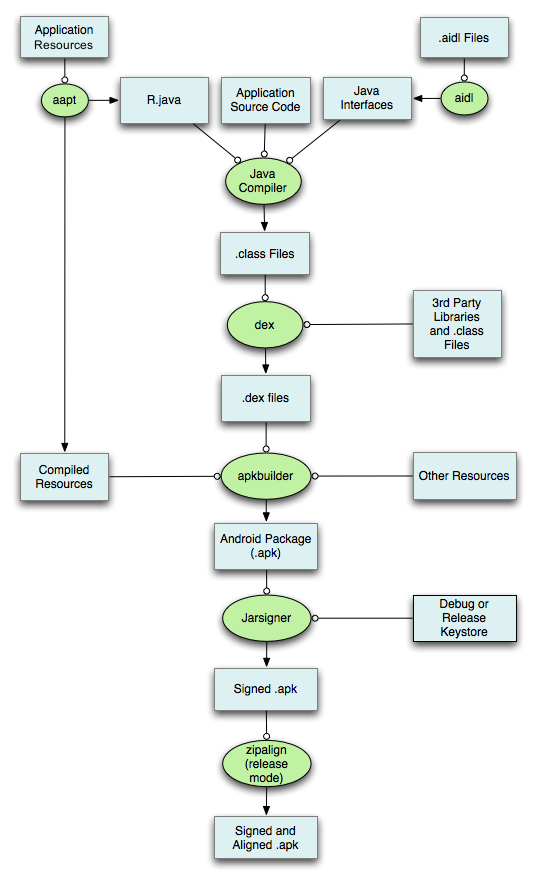
流程基本分为以下几步:
- 打包资源文件,生成R.java文件,使用的是 aapt
- 处理aidl文件,生成相应的Java文件
- 编译项目源代码,生成class文件,使用的是 javac
- 转换所有的class文件,生成classes.dex文件,使用的是 dex 工具
- 打包生成APK文件,使用的是 apkbuilder
- 对APK文件进行签名,使用的是 jarsigner
- 对签名后的APK文件进行对齐处理,使用的是 zipalign
说说 Service 与 Activity 的几种通信方式
如果是后台、前台 Service,可以通过广播的方式通信;如果是绑定 Service,需要通过 Binder 方式通信;如果是 IntentService,可以直接调用 startService 向 IntentService 发送请求。
介绍一下 IntentService
Service 有一个派生类是 IntentService,IntentService 比父类 Service 而言,最大特点是其回调函数onHandleIntent中可以直接进行耗时操作,不必再开线程。其原理是 IntentService 利用了 HandlerThread,它在初始化时已属于工作线程,所以之后的所有操作都是在工作线程中。IntentService 还有一个特点,就是多次调用 onHandleIntent 函数(也就是有多个耗时任务要执行),多个耗时任务会按顺序依次执行。原理是其内置的 Handler 关联了任务队列,Handler 通过 Looper 取任务执行是顺序执行的。这个特点就能解决多个耗时任务需要顺序依次执行的问题。而如果仅用 Service,开多个线程去执行耗时操作,就很难管理。
介绍一下 JobScheduler
JobScheduler 是基于条件执行任务的系统机制,在 Android 5.0 中引入。它的出现是为了解决 Android 对后台任务的限制。它会在特定的条件下执行,可以保证执行,但无法保证执行的时间。
可以通过新建 JobInfo 并新建一个继承自 JobService 的类,重写onStartJob()和onStopJob(),然后使用 JobScheduler.schedule() 的方式向系统提交任务。JobScheduler 是系统服务,其实例需要通过 Context.getSystemService(Context.JOB_SCHEDULER_SERVICE) 来获取。
介绍一下 Context 和 ContextWrapper 和 ContextImpl
ContextWrapper 使用了装饰器模式,它包装了一个 Context,这个 Context 实例会通过ContextWrapper.attachBaseContext()方法来赋值。ContextImpl 是 Context 的具体实现,像调用startActivity()之类的方法都是由它来具体实现的。
Application Context 和 Activity Context 的区别?
Application Context 只有一个实例,无论在何处获取,获取的都是同一个实例;而 Activity Context 获取的是当前 Activtiy 的 Context 实例。
Application Context 如果要用来启动 Activity,需要添加 FLAG_ACTIVITY_NEW_TASK 标识,以启动一个新的任务栈。Activity Context 可以直接启动 Activity
介绍一下 AsyncTask
AsyncTask 是一个适合执行短时任务的工具类,它帮我们处理了 Thread 和 Handler 之间的协作,从而让我们不用直接对这两种类进行操作。它比较适合执行短期任务,如果要执行长时间的任务,那还是使用 Executor、ThreadPoolExecutor 或者 FutureTask。
使用它需要继承 AsyncTask 类并重写四个方法:
onPreExecute():任务开始执行前的回调,此时在主线程doInBackground():任务开始执行的回调,此时在子线程onProgressUpdate():任务有进展时的回调,在主线程onPostExecute():任务完成时的回调,在主线程
AsyncTask 类有三个泛型类:
- Params:参数的类型
- Progress:进度值的单位
- Result:任务结束后返回结果的类型
它必须要在主线程新建实例,它的任务只会执行一次。
它的内部实现是采用了线程池机制,每个线程只能执行一个任务,避免了线程不安全的问题。
它的线程池有两个,分别是工作线程池和备用线程池。当工作线程无法执行任务时,任务会被放到备用线程池中。方法是通过调用ThreadPoolExecutor.setRejectedExecutionHandler()指定一个 Handler 来处理无法执行的问题。
工作线程池:该线程池有1个核心线程,最大线程数量为50,空闲时间为3秒,任务队列使用的是 LinkedBlockingQueue。
备用线程池:5个核心线程,没有非核心线程,任务队列使用的也是 LinkedBlockingQueue。
默认情况下,备用线程池不启用。
AsyncTask 有什么不足?
它的生命周期与 Activity 不是绑定的,导致 Activity 销毁后,AsyncTask 还是会继续执行,直到onPostExecute(),这需要进行额外的处理。还有,如果在执行任务期间,Activity 由于某种原因重新创建了(比如屏幕旋转或销毁又恢复),AsyncTask 执行结束也不会更新 UI 了,甚至还有可能引起NullPointerException。
另外,AsyncTask 的线程池数量是 50,后来被修改为 20,所以执行能力有限。
为什么不能在子线程更新 UI?
原则上来说,是为了线程安全。
因为 Android 在访问 UI 时是没有加锁的,如果能在多个线程下访问 UI,则有可能会导致 UI 处于不可预期的状态。如果要给 UI 加锁,会让 UI 控件变得复杂和低效,同时也有可能会引起其他线程的阻塞。所以在 Android 中,每当更新 UI 的时候,会有 layout 过程,这个过程中会调用到ViewRootImpl.checkThread()检查当前线程,如果不是主线程,就会直接抛出异常。
那么,子线程有能力更新 UI 吗?有。在onCreate()方法中去更新 UI,是可以的,因为这个时候 ViewRootImpl 尚未创建,还没有到 layout 阶段,所以此时是可以修改 UI 的。
ANR 定位和修正?
ANR 的出现是由于主线程的 Looper 无法在规定时间内取出下一条消息导致的。每当发生 ANR,可以在 /data/anr/traces.txt 文件中找到 ANR 产生的代码位置,然后就可以根据它修正。
同时,尽量避免在 BroadcastReceiver 中进行耗时操作,如果超过10秒,则会引起 ANR。主线程上的阈值是 5 秒。Service 中后台、前台、绑定 Service 分别是 20秒、5秒和200秒。
有什么方法可以避免 OOM ?
可以从四个方面着手。
首先是减小对象的内存占用,其次是内存对象的重复利用,然后是避免对象的内存泄露,最后是内存使用策略优化。
1)使用更加轻量的数据结构
例如,我们可以考虑使用ArrayMap/SparseArray而不是HashMap等传统数据结构,下图演示了HashMap的简要工作原理,相比起Android系统专门为移动操作系统编写的ArrayMap容器,在大多数情况下,都显示效率低下,更占内存。通常的HashMap的实现方式更加消耗内存,因为它需要一个额外的实例对象来记录Mapping操作。另外,SparseArray更加高效在于他们避免了对key与value的autobox自动装箱,并且避免了装箱后的解箱。
2)避免在Android里面使用Enum
3)减小Bitmap对象的内存占用
Bitmap是一个极容易消耗内存的大胖子,减小创建出来的Bitmap的内存占用是很重要的,通常来说有下面2个措施:
inSampleSize:缩放比例,在把图片载入内存之前,我们需要先计算出一个合适的缩放比例,避免不必要的大图载入。
decode format:解码格式,选择ARGB_8888/RBG_565/ARGB_4444/ALPHA_8,存在很大差异。
4)使用更小的图片
在设计给到资源图片的时候,我们需要特别留意这张图片是否存在可以压缩的空间,是否可以使用一张更小的图片。尽量使用更小的图片不仅仅可以减少内存的使用,还可以避免出现大量的InflationException。假设有一张很大的图片被XML文件直接引用,很有可能在初始化视图的时候就会因为内存不足而发生InflationException,这个问题的根本原因其实是发生了OOM。
在Android上面最常用的一个缓存算法是LRU(Least Recently Use)
5)复用系统自带的资源
Android系统本身内置了很多的资源,例如字符串/颜色/图片/动画/样式以及简单布局等等,这些资源都可以在应用程序中直接引用。这样做不仅仅可以减少应用程序的自身负重,减小APK的大小,另外还可以一定程度上减少内存的开销,复用性更好。但是也有必要留意Android系统的版本差异性,对那些不同系统版本上表现存在很大差异,不符合需求的情况,还是需要应用程序自身内置进去。
6)注意在ListView/GridView等出现大量重复子组件的视图里面对ConvertView的复用
7)Bitmap对象的复用
在ListView与GridView等显示大量图片的控件里面需要使用LRU的机制来缓存处理好的Bitmap。
利用inBitmap的高级特性提高Android系统在Bitmap分配与释放执行效率上的提升(3.0以及4.4以后存在一些使用限制上的差异)。使用inBitmap属性可以告知Bitmap解码器去尝试使用已经存在的内存区域,新解码的bitmap会尝试去使用之前那张bitmap在heap中所占据的pixel data内存区域,而不是去问内存重新申请一块区域来存放bitmap。利用这种特性,即使是上千张的图片,也只会仅仅只需要占用屏幕所能够显示的图片数量的内存大小。
8)避免在onDraw方法里面执行对象的创建
类似onDraw等频繁调用的方法,一定需要注意避免在这里做创建对象的操作,因为他会迅速增加内存的使用,而且很容易引起频繁的gc,甚至是内存抖动。
9)StringBuilder
在有些时候,代码中会需要使用到大量的字符串拼接的操作,这种时候有必要考虑使用StringBuilder来替代频繁的“+”。
避免对象的内存泄露
内存对象的泄漏,会导致一些不再使用的对象无法及时释放,这样一方面占用了宝贵的内存空间,很容易导致后续需要分配内存的时候,空闲空间不足而出现OOM。显然,这还使得每级Generation的内存区域可用空间变小,gc就会更容易被触发,容易出现内存抖动,从而引起性能问题。
10)注意Activity的泄漏
通常来说,Activity的泄漏是内存泄漏里面最严重的问题,它占用的内存多,影响面广,我们需要特别注意以下两种情况导致的Activity泄漏:
内部类引用导致Activity的泄漏
最典型的场景是Handler导致的Activity泄漏,如果Handler中有延迟的任务或者是等待执行的任务队列过长,都有可能因为Handler继续执行而导致Activity发生泄漏。此时的引用关系链是Looper -> MessageQueue -> Message -> Handler -> Activity。为了解决这个问题,可以在UI退出之前,执行remove Handler消息队列中的消息与runnable对象。或者是使用Static + WeakReference的方式来达到断开Handler与Activity之间存在引用关系的目的。
Activity Context被传递到其他实例中,这可能导致自身被引用而发生泄漏。
内部类引起的泄漏不仅仅会发生在Activity上,其他任何内部类出现的地方,都需要特别留意!我们可以考虑尽量使用static类型的内部类,同时使用WeakReference的机制来避免因为互相引用而出现的泄露。
11)考虑使用Application Context而不是Activity Context
对于大部分非必须使用Activity Context的情况(Dialog的Context就必须是Activity Context),我们都可以考虑使用Application Context而不是Activity的Context,这样可以避免不经意的Activity泄露。
12)注意临时Bitmap对象的及时回收
虽然在大多数情况下,我们会对Bitmap增加缓存机制,但是在某些时候,部分Bitmap是需要及时回收的。例如临时创建的某个相对比较大的bitmap对象,在经过变换得到新的bitmap对象之后,应该尽快回收原始的bitmap,这样能够更快释放原始bitmap所占用的空间。
需要特别留意的是Bitmap类里面提供的createBitmap()方法:
这个函数返回的bitmap有可能和source bitmap是同一个,在回收的时候,需要特别检查source bitmap与return bitmap的引用是否相同,只有在不等的情况下,才能够执行source bitmap的recycle方法。
13)注意WebView的泄漏
Android中的WebView存在很大的兼容性问题,不仅仅是Android系统版本的不同对WebView产生很大的差异,另外不同的厂商出货的ROM里面WebView也存在着很大的差异。更严重的是标准的WebView存在内存泄露的问题,看这里WebView causes memory leak - leaks the parent Activity。所以通常根治这个问题的办法是为WebView开启另外一个进程,通过AIDL与主进程进行通信,WebView所在的进程可以根据业务的需要选择合适的时机进行销毁,从而达到内存的完整释放。
14)资源文件需要选择合适的文件夹进行存放
我们知道hdpi/xhdpi/xxhdpi等等不同dpi的文件夹下的图片在不同的设备上会经过scale的处理。例如我们只在hdpi的目录下放置了一张100100的图片,那么根据换算关系,xxhdpi的手机去引用那张图片就会被拉伸到200200。需要注意到在这种情况下,内存占用是会显著提高的。对于不希望被拉伸的图片,需要放到assets或者nodpi的目录下。
15)谨慎使用static对象
因为static的生命周期过长,和应用的进程保持一致,使用不当很可能导致对象泄漏,在Android中应该谨慎使用static对象。
16)特别留意单例对象中不合理的持有
虽然单例模式简单实用,提供了很多便利性,但是因为单例的生命周期和应用保持一致,使用不合理很容易出现持有对象的泄漏。
17)珍惜Services资源
18)优化布局层次,减少内存消耗
越扁平化的视图布局,占用的内存就越少,效率越高。我们需要尽量保证布局足够扁平化,当使用系统提供的View无法实现足够扁平的时候考虑使用自定义View来达到目的。
19)谨慎使用“抽象”编程
很多时候,开发者会使用抽象类作为”好的编程实践”,因为抽象能够提升代码的灵活性与可维护性。然而,抽象会导致一个显著的额外内存开销:他们需要同等量的代码用于可执行,那些代码会被mapping到内存中,因此如果你的抽象没有显著的提升效率,应该尽量避免他们。
20)谨慎使用多进程
使用多进程可以把应用中的部分组件运行在单独的进程当中,这样可以扩大应用的内存占用范围,但是这个技术必须谨慎使用,绝大多数应用都不应该贸然使用多进程,一方面是因为使用多进程会使得代码逻辑更加复杂,另外如果使用不当,它可能反而会导致显著增加内存。当你的应用需要运行一个常驻后台的任务,而且这个任务并不轻量,可以考虑使用这个技术。
一个典型的例子是创建一个可以长时间后台播放的Music Player。如果整个应用都运行在一个进程中,当后台播放的时候,前台的那些UI资源也没有办法得到释放。类似这样的应用可以切分成2个进程:一个用来操作UI,另外一个给后台的Service。
什么情况导致内存泄漏?
非静态内部类持有外部类的实例导致内存泄漏。
Activity 实例被静态实例持有,导致 Activity 无法被释放。
Cursor 未关闭。
自定义的监听器未清空。
介绍一下 LruCache
Android 线程有没有上限?
当然有上限。但这个值并不固定的,分配给应用程序的内存空间是有限的,当创建线程消耗的资源大于分配的内存时,就会导致 Out of Memory。
ListView 重用的是什么?
ConvertView 是从 AbsListView 的 RecyclerBin 中拿出来的 ScrapView。该 View 在首次 layout 过程时会通过 LayoutInflator 创建,在之后展示在屏幕上时会传入Adapter.getView()中,可以对它进行复用,避免再次渲染。
屏幕适配的处理技巧都有哪些?
- 基于自适应尺寸的 wrap_content、match_parent,weight 避免固定的尺寸单位。
- 使用基于控件相对位置的 RelativeLayout,现在更加推荐使用约束布局 ConstraintLayout,对于布局性能以及扁平化更具有优势。
- 考虑使用自动拉伸的 .9 图或者使用矢量图,矢量图可以保证图片不受拉伸影响而导致失真。
- 布局使用限定符。
如何实现 ViewPager + Fragment 的懒加载?
懒加载主要是处理 Fragment 第一次对用户可见、每次对用户可见、每次对用户不可见。在这些时间点交给实现类来做像网络请求、中断、数据处理等。
Fragment 的生命周期是这样的:onAttach()→onCreate()→onCreatedView()→onActivityCreated()→onStart()→onResume()→onPause()→onStop()→onDestroyView()→onDestroy()→onDetach()。
在这里面,我们需要关注的是这几个方法:onCreatedView() + onActivityCreated() + onResume + onPause + onDestroyView。还有两个非生命周期方法:setUserVisibleHint() 和 onHiddenChanged()。
在 ViewPager + Fragment 的配合时,我们在大多数情况下使用的是 FragmentPagerAdapter 或者 FragmentPagerStateAdapter,前者在 Fragment 不见的时候不会走onDetach()方法,而后者会。
对于 Fragment 的可见状况,我们需要两个标志位:**Fragment 创建完成的标志位isViewCreated和第一次可见的标志位isFirstVisible。对于它不可见的状态,和再次回到可见状态的判断,我们还需要再加一个标志位:currentVisibleState**。
Recycleview 和 ListView 的区别
缓存机制不同。ListView 中是 RecyclerBin 类,有 ActiveViews 和 ScrapViews 两个数组,用于存放正显示在屏幕上的 View 和暂时看不见的 View。它缓存的是 View。而 RecyclerView 中是 Recycler 类,比 ListView 要多两级缓存,有 AttachedScrapView、CacheViews、支持用户自定义的 ViewCacheExtension 和 RecyclerPool。它缓存的是 ViewHolder。
RecyclerView 支持局部刷新,ListView 不支持。
自定义 View 的流程是什么?
自定义 View 分为两大块:自定义控件和自定义容器。
自定义View必须重写两个构造方法:
- 只有 Context 参数的 ,用于在java代码中new对象使用
- Context + AttributSet。 主要用于解析在 xml 中的自定义属性
重写三个方法:
onMesure:计算出控件的大小onLayout:计算出控件的位置onDraw:进行绘制
布局过程:
- measure过程:调用了
measureChildren方法,执行了所有子控件的measure方法测绘出所有的子控件的大小。
调用setMeasureDimension方法设置测绘后的大小。 - layout过程:调用
requestLayout方法,layout方法。在调用getChildCount方法后获取到子条目数量,用循环遍历出每一个子条目的对象。 通过子控件的layout方法 给子控件设置摆放位置。 - draw过程:首先调用ViewGroup的
dispatchDraw()方法绘制ViewGroup。然后调用View中的draw方进行绘制。
View 的事件传递机制是怎样的?
由电信号转换为输入事件,然后交给了 InputManagerService,再交给 WindowInputEventReceiver,最后经过传递交给了 ViewRootImpl 的processPointEvent方法,其中又调用了 DecorView 的dispatchPointerEvent方法,又调用了dispatchTouchEvent方法,该方法在 View 中。同时,DecorView 也重写了dispatchTouchEvent方法,它将事件交给了 Activity,(你问我如何交的?在 Activity 的 onAttach()方法中,就设置了一个 Callback 给 DecorView。) Activity 重写了dispatchTouchEvent方法,在其中调用了 PhoneWindow 的superDispatchTouchEvent方法,PhoneWindow 接着调用了 DecorView 的superDispatchTouchEvent方法,在这个方法里又调用了super.dispatchTouchEvent(),而 DecorView 的 super 其实就是 ViewGroup,也就是兜兜转转交给了 DecorView,再按照分发机制从 ViewGroup 下发到所有的子 View。
ViewGroup.dispatchTouchEvent()会先判断是否要拦截事件,通过onInterceptTouchEvent方法,如果不拦截,就开始给合适的子 View 进行事件的派发,也就是调用子 View 的dispatchTouchEvent。如果有任意一个子 View 消耗此次事件,也即dispatchTouchEvent返回了true,那么派发就中止,表示事件已经被消耗;如果没有任何一个子 View 消耗此次事件,也即所有的子 View 的dispatchTouchEvent都返回了false,那么 ViewGroup 就自己消耗此次事件。如果 ViewGroup 也没有消耗,那就会再向上返回,直到 Activity 的onTouchEvent方法。
View.onTouchEvent()方法是在View.dispatchTouchEvent()中被调用的,返回true表示消耗此次事件,返回false表示不消耗。如果不消耗,那么在同一个事件序列中,就不再接收到事件了。
ViewGroup.onInterceptTouchEvent()方法是在ViewGroup.dispatchTouchEvent()中被调用的,用来判断是否要拦截某个事件。如果当前 ViewGroup 拦截了某个事件,那么在同一个事件序列当中,此方法不会被再次调用,返回结果表示是否拦截当前事件。这个方法只有 ViewGroup 中有,View 中没有。它起到的作用是分流,返回false或者返回super.xxx是向下级 View 或者 ViewGroup 传递,返回true是把事件交给自己的onTouchEvent处理。
ViewGroup默认不拦截任何事件。
onTouchListener、onTouchEvent、onClickListener的优先级
onTouchListener >> onTouchEvent >> onClickListener >> onClick
Handler、Looper、MessageQueue、Message 的关系
Message:负责承载要传递的数据,包括消息的 code,要传递的参数等等。Message 中有个『池』的概念,其实就是一个静态变量sPool,它本身包含下一条消息的引用,Message 每次使用obtain()方法拿取的时候,是拿取的队列的头,然后将sPool置为队列的第二个值。这个数据结构是个链表。
MessageQueue:负责维护 Message 的生命周期,提供enqueueMessage()和next()两个方法,用来做『进』『出』的操作。Message 如果不用了,那么就把它回收,也就是清空它的内部数据,但是不销毁这个实例,这样下次有新消息的时候,就直接赋值,而不用建立新的 Message 实例,节省内存空间。在『出』操作的时候,还会去判断 Message 的发送时间是不是到了,如果还没到,就等待相应的时间,等到时间到了,取出并返回,这里也是用一个死循环来实现的。同时会有nativePollOnce()方法来实现阻塞,而不是让死循环一直运行。
Looper:一个死循环,使用 ThreadLocal 机制去获取当前调用它的线程下的 Looper 实例。prepare 的过程中,会实例化一个 MessageQueue。loop 过程中,会尝试调用MessageQueue.next()方法,来获取 Message,如果有的话,就给取出的 Message 中的 handler 发送消息,让该 handler 来处理这个 Message。如果没有的话,在next()方法中会一直被阻塞。
Handler:负责处理 Message。在初始化时可以传入 Looper,那它就会在对应的线程下处理 Message。在调用Handler.post()方法的时候,新建的 Message 会被 Handler 交给 Looper 中的 MessageQueue,并使用它的enqueueMessage()添加到Message.next中。
主线程的 Looper 死循环为什么不会导致 ANR?
这个问题其实算是偷换概念。
首先,死循环不是造成 ANR 的必然原因,ANR 是因为消息队列中的消息没有得到及时处理才造成的,比如 BroadcastReceiver 的onReceive()方法中处理事务超过了10秒,比如onTouch()事件超过了5秒,才会导致 ANR。
第二,主线程的 Looper 死循环,最多也就会导致个 OOM,但是主线程在没有消息时也会休眠、进入阻塞状态,当有新消息来临时,再被唤醒,分发消息,实际上对于内存的消耗非常小。
第三,如果主线程的 Looper 不循环了,那main()方法就抛出一个异常结束了,就整个应用就退出了。
Looper 多次 prepare 会不会有问题?
会。会抛出 RuntimeException:Only one Looper may be created per thread。
App 点击到 Activity 出现的流程?
- 源进程调用
startActivity(),最终会调用到Instrumentation.execStartActivity()方法; - 通过 Binder 调用 ActivityTaskManagerService 的
startActivity()方法; - ATMS 会使用 ActivityStack 类和 ActivityStackSupervisor 类来处理 Task 与 Activity 的入栈操作;
- 接着在
ActivityStackSupervisor.realStartActivityLocked()方法中,使用提交事务的方法,创建一个启动 Activity 的事务,并提交给 ClientLifecycleManager; - ClientLifecycleManager 会通过 Binder 调用 ActivityThread 的
scheduleTransaction()方法,该方法会向 ActivityThread 中的 Handler 发送一个消息; - Handler 接收消息后,利用 TransactionExecutor 按顺序执行事务;
- 在这个『启动 Activity』的事务回调中,又调用了 ActivityThread 的
handleLaunchActivity()方法,进而又调用了performLaunchActivity()方法; - 在这个方法中,利用反射创建了 Activity 的实例,如果需要的话,还利用反射创建了 Application 的实例,并调用
Activity.attach()方法,创建 PhoneWindow、绑定 Context; - 最后调用了
Instrumentation.callActivityOnCreate()方法,执行了 Activity 的onCreate()生命周期方法; - 接着 TransactionExecutor 又开始执行生命周期事务,最后依次调用到
onStart()、onResume()。
介绍一下 Binder
介绍一下优化相关的
启动优化、内存优化、埋点优化等等。
Serializable 和 Parcelable 有什么不同?
Serializable 和 Parcelable 都是用来序列化/反序列化,方便将对象在网络上进行传输或本地保存。
Serializable 是 Java 提供的类,在使用时只需要 implement Serializable,然后声明一个 serialVersionUID 就可以了。
Parcelable 是 Android 提供的类,在使用时相对复杂。
- 类本身要实现 Parcelable 接口
- 有一个非空的静态成员变量叫
CREATOR,并且它要实现Parcelable.Creator接口- 覆写
createFromParcel(Parcel in)方法 - 覆写
newArray(int size)方法
- 覆写
- 覆写
describeContents()方法 - 覆写
writeToParcel(Parcel dest, int flags)方法
两种类的对比如下:
- Serializable 代码量少,Parcelable 代码量多。
- 在内存间传递数据的时候,Parcelable 比 Serializable 性能高、内存开销方面较小,所以推荐使用 Parcelable;而在需要保存数据到本地或者进行网络传输时,使用 Serializable。
- Serializable 在序列化时使用的是反射的技术,会产生大量的临时变量,从而引起频繁的 GC。而 Parcelable 方式的实现原理是将一个完整的对象进行字节化,而字节化之后的每一部分都是 Intent 所支持的数据类型,这样也就实现传递对象的功能了。
Jetpack 介绍一下
Jetpack 是一套库,它里面有非常多的由 Google 提供的标准库,比如 Data Binding、Lifecycle、LiveData、Navigation、Room、ViewModel、WorkManager 等。意图将开发中用到的方方面面的第三方库都进行『消灭』。
排查内存泄漏
常见的算法
100 MB的大图如何显示 ?
利用 BitmapRegionDecoder —— 区域解码器,有了这个我们就可以自定义一块矩形的区域,然后根据手势来移动矩形区域的位置就能慢慢看到整张图片了。