目前常见的几种缓存算法包括但不限于 FIFO、LRU、LFU、MRU。下面我们一一介绍并深入一下。
FIFO 算法
FIFO(First In First Out)是比较常见的算法了,队列(Queue)就是实现了这种算法的最好例子。这是最简单、最公平的一种算法思想,它认为如果一个数据是最先进入的,那么在将来它被访问的可能性是最小的。空间满的时候,最先进入的数据会被淘汰掉。
下图展示 FIFO 算法在访问顺序是 A、B、C、D、E、D、F 的情况下,缓存列表的更新情况(链表大小假定为4):

白色代表无数据,灰色代表未更新数据,绿色代表被更新数据
FIFO 的实现比较简单,可以维护一个FIFO队列,按照时间顺序将各数据链接起来组成队列,并将置换指针指向队列的队首。再进行置换时,只需把置换指针所指的数据(页面)顺次换出,并把新加入的数据插到队尾即可。
优点:实现简单
缺点:判断一个缓存算法优劣的指标就是命中率,而 FIFO 算法的一个显著的缺点是,在某些特定的时刻,命中率反而会随着缓存量的增加而减少,这称为 Belady 现象。产生 Belady 现象的原因是,FIFO 置换算法与进程访问内存的动态特征是不相容的,被置换的数据往往是被频繁访问的,或者没有给进程分配足够的缓存空间,因此 FIFO 算法会使一些数据频繁地被替换和重新申请内存,从而导致命中率降低。因此,现在几乎不再使用 FIFO 算法。
LRU 算法
LRU
LRU(Least recently used)算法会根据数据的历史访问记录来进行淘汰数据,其核心思想是『如果数据最近被访问过,那么将来被访问的几率也更高』。
下图展示了访问顺序是 A、B、C、D、E、D、F 情况下,缓存列表的更新情况:
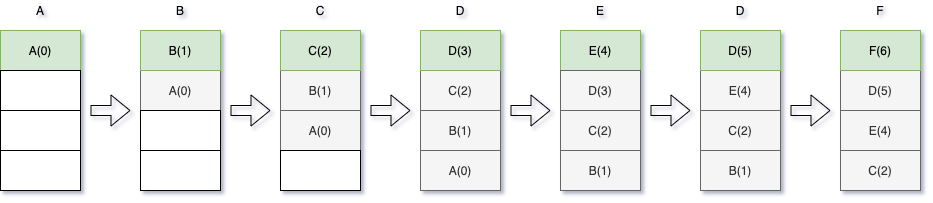
白色代表无数据,灰色代表未更新数据,绿色代表被更新数据
由上图可以总结一下 LRU 算法的几个特点:
- 新来的数据会插入链表的头部
- 如果链表已满(达到最大长度),则会丢弃掉链表尾部的数据
- 如果访问时命中,则要移动数据的位置注1
LRU 的实现一般是使用 LinkedHashMap,即包含了用来表示『位置』的双向链表,也包含用来『存储和获取』的 HashMap。
优点:实现起来相对简单。
缺点:当存在热点数据时,LRU 的效率很好;但偶发性的、周期性的批量操作会导致 LRU 命中率急剧下降,缓存污染情况比较严重。
我们来写个代码简单实现一下 LRU 算法:
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.logging.Level;
import java.util.logging.Logger;
public class LruCache<K, V> extends LinkedHashMap<K, V> {
private int cacheSize;
public LruCache(int cacheSize) {
// 三个参数分别是:初始大小、负载因子、是否开启访问顺序(accessOrder)
// 开启访问顺序后,被命中的数据会移动到链表的头部
super(16, (float) 0.75, true);
this.cacheSize = cacheSize;
}
// 复写该方法,来决定是否要移除最旧的数据,该方法在 LinkedHashMap 中默认返回 false
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > cacheSize;
}
public void print()
{
Iterator<K> itr = this.keySet().iterator();
while (itr.hasNext()) {
System.out.print(itr.next() + " ");
}
System.out.println();
}
public static void main(String[] args) {
LruCache<String, Integer> lruCache = new LruCache<String, Integer>(4);
for(int i = 0; i < 10; i++) {
lruCache.put("K" + i, i);
}
lruCache.print();
lruCache.put("K10", 10);
lruCache.print();
lruCache.get("K7");
lruCache.print();
}
}
输出结果如下:
K6 K7 K8 K9
K7 K8 K9 K10
K8 K9 K10 K7
很明显这个实现类是线程不安全的,因为 LinkedHashMap 本身就是线程不安全的。
LRU-K
LRU-K 中的 K 代表最近使用的次数,所以,LRU 可以被认为是 LRU-1。LRU-K 的主要目的是为了解决 LRU 算法『缓存污染』的问题,其核心思想是将『最近使用过1次』的判断标准扩展为『最近使用过K次』。
于是,相比 LRU,LRU-K 需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到 K 次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K 会淘汰第 K 次访问时间距当前时间最大的数据。
Android 中的 LruCache
Android 中的 LruCache 实现与上面直接使用 LinkedHashMap 的特性不一样,它自定义了数据插入的位置、获取的策略和丢弃的策略。
话不多说,直接上代码,在注释中进行详解:
// android.util.LruCache.java
package android.util;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 这是一个缓存,里面的数据都是强引用,包含有限数量的数据。
* 每次当某个数据被访问,它会被移动到队列的头部。当缓存已满,新数据来临时,队列尾部的数据会被丢弃,GC 就可以回收它了。
*
* 如果你缓存的数据需要被显式地释放掉,那就重写 entryRemoved 方法。
*
* 如果缓存未命中时,需要计算并获取对应的key,重写 create 方法。
*
* 默认情况下,缓存的大小以 Entry 的个数界决的,你可以重写 sizeOf 方法用不同的单位来决定缓存空间的大小。
* 比如,下面这个缓存的上限是 4MB 的 bitmap:
*
* int cacheSize = 4 * 1024 * 1024; // 4MiB
* LruCache<String, Bitmap> bitmapCache = new LruCache<String, Bitmap>(cacheSize) {
* protected int sizeOf(String key, Bitmap value) {
* return value.getByteCount();
* }
* }
*
* 这个 LruCache 类是线程安全的。可以用下面的方法来安全地插入和获取数据:
*
* synchronized (cache) {
* if (cache.get(key) == null) {
* cache.put(key, value);
* }
* }
*
* 该类不允许 null key 或者 null value。当 get、put、remove 方法返回 null 时,它的意思很明确:key 不在缓存中
*/
public class LruCache<K, V> {
private final LinkedHashMap<K, V> map;
private int size;
private int maxSize;
// 插入次数
private int putCount;
// 新建次数
private int createCount;
// 丢弃次数
private int evictionCount;
// 命中次数
private int hitCount;
// 未命中次数
private int missCount;
// maxSize 就是没有重写 sizeOf 方法的缓存大小,也即 Entry 的条目数量
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
public void resize(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
synchronized (this) {
this.maxSize = maxSize;
}
trimToSize(maxSize);
}
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
// 尝试根据 key 创建一个 value。
// 因为这段代码不是同步的,所以在 create 方法结束的时候,map 的内容可能已经变化了。
// 如果 create 方法返回的值与 map 中的值冲突,我们就释放 create 的值,并保留 map 中的值。
// 目前 create 总是返回 null。
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
}
// value 会被放到队列的头部
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
private void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) {
break;
}
// BEGIN LAYOUTLIB CHANGE
// get the last item in the linked list.
// This is not efficient, the goal here is to minimize the changes
// compared to the platform version.
Map.Entry<K, V> toEvict = null;
for (Map.Entry<K, V> entry : map.entrySet()) {
toEvict = entry;
}
// END LAYOUTLIB CHANGE
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
public final V remove(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V previous;
synchronized (this) {
previous = map.remove(key);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, null);
}
return previous;
}
// 这个方法在调用时,是线程不安全的
// 当有 Entry 被丢弃或删除时调用。
protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) {}
// 这个方法在调用时,是线程不安全的
protected V create(K key) {
return null;
}
...
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
...
}
可见,Android 对 LruCache 有了自己的实现,最重要的是,它是线程安全的,但是效率会相对低一些,不过缓存的使用概率本身相对较低,所以稍低的效率也是可以忍受的。
LFU 算法
LFU(Least Frequently Used,最近最少使用)也是一种常见的缓存算法。它认为如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
在实现时,考虑到 LFU 会淘汰访问频率最小的数据,我们需要一种合适的方法按大小顺序维护数据访问的频率。LFU 算法本质上可以看做是一个 top K 问题(K = 1),即选出频率最小的元素,因此我们很容易想到可以用二项堆来选择频率最小的元素,这样的实现比较高效。最终实现策略为小顶堆+哈希表。
缺点:最新加入的数据常常会被踢除,因为其起始方法次数少。
MRU 算法
MRU(Most Recently Used,最近最常使用)算法的思想与 LRU 算法正好相反,它认为如果一个数据最近被访问过,那么它接下来被访问的概率就会更低。
附注
注1
在移动数据的位置时,在 java1.7(含)之前采用的是头插法,数据会被移动到链表的头部。而在 java1.8 之后,采用了尾插法,所以移动数据的话,就会被移动到链表的尾部。
我们看看代码是如何写的:
// LinkedHashMap java1.7
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
private transient Entry<K,V> header;
...
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
...
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
...
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
// 这里可以看出,将被访问的 Entry 重新放置在了 header 的前面,也即成为了新的链表头
addBefore(lm.header);
}
}
}
...
}
// LinkedHashMap java1.8
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
...
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head; // 表头,最老的数据
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail; // 表尾,最新的数据
...
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}